GPVデータ
GPVデータ(Grid Point Value)は格子点毎の気象予報の値持つデータです。
詳細はこちらが参考になります。 ods.n-kishou.co.jp
気象庁からサンプルデータも取得可能です。
今回は「メソ数値予報モデルGPV (MSM)」を使っていきます。

データ形式や特性について
フォーマット
GPVデータはGRIB2というフォーマットで配布されています。上記気象庁のサイトのガイドに内部仕様が記載されています。
サンプルデータ
サンプルデータとして以下の2ファイルが展開できます。
- Z__C_RJTD_20171205000000_MSM_GPV_Rjp_L-pall_FH00-15_grib2.bin
- Z__C_RJTD_20171205000000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin
Pythonのpygribというライブラリを使って、`Z__C_RJTD_20171205000000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin`の方の中身を見てみます。
import pygrib with pygrib.open("./sample_data/Z__C_RJTD_20171205000000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin") as gpv_file: messages = gpv_file.select(name="Temperature") # 気温情報のみをSELECT [print(msg.validDate,msg) for msg in messages]
以下のように出力されます。
2017-12-05 00:00:00 5:Temperature:K (instant):regular_ll:heightAboveGround:level 1.5 m:fcst time 0 hrs:from 201712050000 2017-12-05 01:00:00 15:Temperature:K (instant):regular_ll:heightAboveGround:level 1.5 m:fcst time 1 hrs:from 201712050000 2017-12-05 02:00:00 27:Temperature:K (instant):regular_ll:heightAboveGround:level 1.5 m:fcst time 2 hrs:from 201712050000 --省略 2017-12-05 14:00:00 171:Temperature:K (instant):regular_ll:heightAboveGround:level 1.5 m:fcst time 14 hrs:from 201712050000 2017-12-05 15:00:00 183:Temperature:K (instant):regular_ll:heightAboveGround:level 1.5 m:fcst time 15 hrs:from 201712050000
例えば以下のエントリなら、2017-12-05 00:00 時点の 2017-12-05 10:00:00 の気温(Temperature)の予報データが入っています。
ここにファイル名にある FH00-15 が表すように 00時~15時までの16エントリが入っています。
2017-12-05 10:00:00 123:Temperature:K (instant):regular_ll:heightAboveGround:level 1.5 m:fcst time 10 hrs:from 201712050000
MSMの場合は、エントリ毎に緯度×経度で505×481格子点が入っています。一つ取り出してみたところが以下です。
import pygrib lat = 35.6 lon = 139.71 with pygrib.open("./sample_data/Z__C_RJTD_20171205000000_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin") as gpv_file: messages = gpv_file.select(name="Temperature") # 気温情報のみを抽出 for msg in messages: p = msg.data(lat1=lat-0.025,lat2=lat+0.025,lon1=lon-0.03125,lon2=lon+0.03125) # 指定した緯度・経度に近い格子点を選択 print(f"予報時刻 {msg.validDate} lat={p[1][0][0]:.3f} lon={p[2][0][0]:.3f} Temperature={p[0][0][0] - 273.15}")
予報時刻 2017-12-05 00:00:00 lat=35.600 lon=139.688 Temperature=9.966958618164085 予報時刻 2017-12-05 01:00:00 lat=35.600 lon=139.688 Temperature=11.549844360351585 予報時刻 2017-12-05 02:00:00 lat=35.600 lon=139.688 Temperature=12.499414062500023 --省略 予報時刻 2017-12-05 13:00:00 lat=35.600 lon=139.688 Temperature=7.91053161621096 予報時刻 2017-12-05 14:00:00 lat=35.600 lon=139.688 Temperature=7.602075195312523 予報時刻 2017-12-05 15:00:00 lat=35.600 lon=139.688 Temperature=7.19690856933596
データの特性
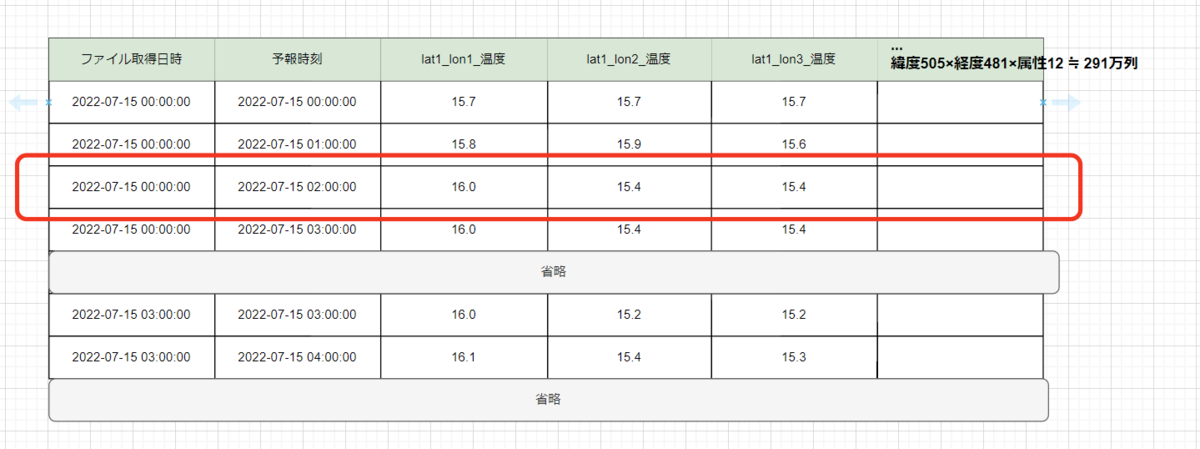
その時点の、予報時刻毎の格子点に対する気象情報がスナップショットで格納されていることになります。
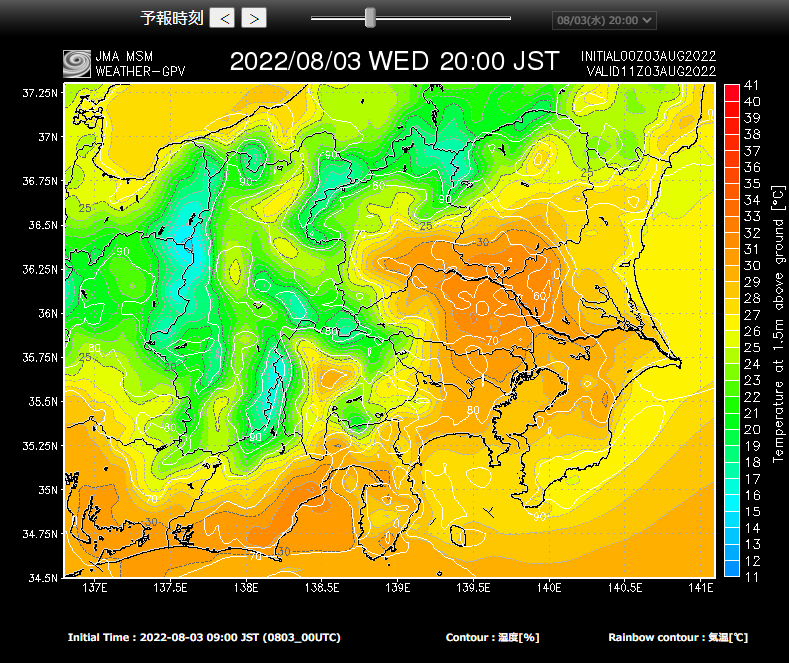
以下のサイトもちょうど同じデータ使っているはずでして、この図を作るためには 2022-08-03 09:00 JST 時点に取得したGRIB2ファイルの 2022-08-03 20:00 JST の気温の予報情報を展開することになります。
スナップショットなので、特定時点の各格子点の情報を横に展開するには便利なデータフォーマットと言えます。
※このサイトとても便利なのでオススメです。モバイル版もあります。
二次元テーブルで表すとすると以下のようなイメージになります。
要件
やりたいこと
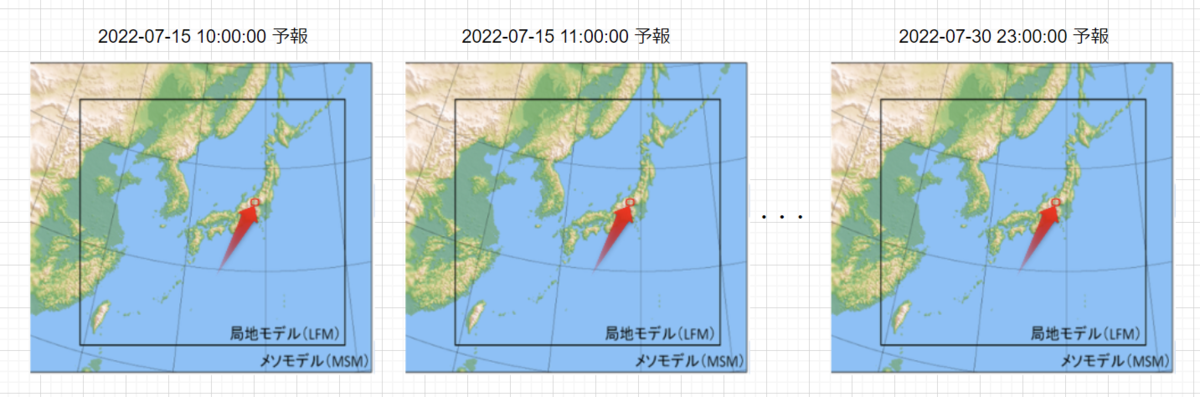
このデータに対して格子点に対する時系列分析をしたいという要件が出ました。
イメージにすると以下の通りです。
先程の2次元表に表すとすると以下のようになります。
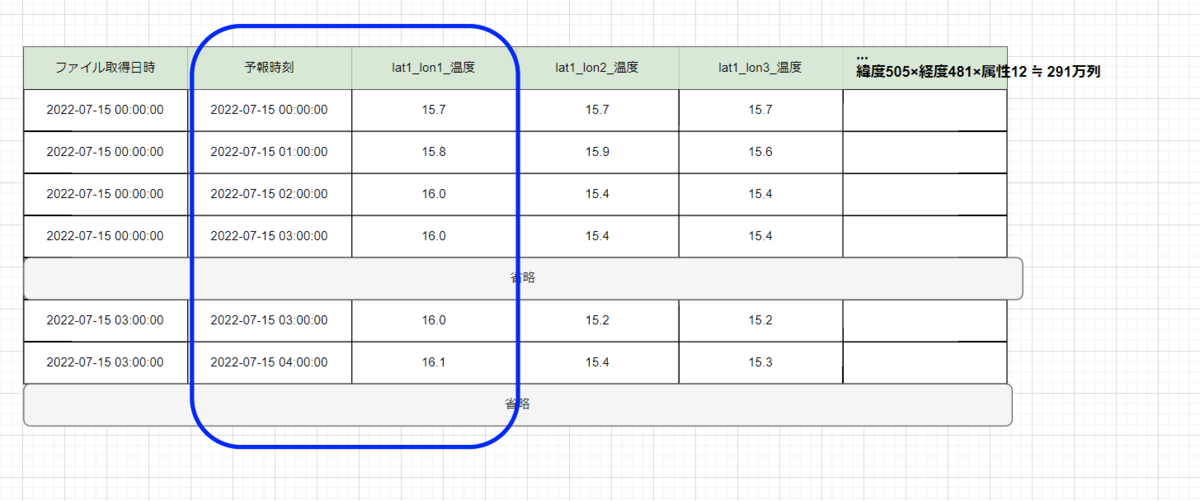
テーブルの方の青枠、縦の方向に取得したいことになります。
GRIB2ファイルから取得しようとすると以下のような観点で、非効率効率と言えます。
- 複数(大量)のにファイルを跨いでアクセスする必要がある
- ファイル毎にアクセスしたいポイントは極一部
GRIB2ファイルフォーマットの意図と違う方法になるので、フォーマット変換をして、AWS上の最適なサービスを模索してみることにしました。
その他ポイント
データロード
- 3時間毎に最新データの一回のロードが必要。1時間いないではロードしたい。
- ロードコストは最小に抑えたい
データ容量
- 過去データまで遡った分析をしたい現時点で10年分ほどデータがある
クエリ
- レイテンシ要件は厳しくない(数秒以内にレスポンスなどは不要)
- クエリ頻度も高く無い(分析対象として利用)
- 格子点の特定要素の時系列分析をしたい
- 例:緯度=35.6 経度=139.71の格子点の温度に関して、予報データを2年分取得
検討
データ形式調査
メソ数値予報モデルGPVを利用します。先程も使っていた Z__C_RJTD_yyyyMMddhhmmss_MSM_GPV_Rjp_Lsurf_FH00-15_grib2.bin のようなファイル名のものです。
| 項目 | 数 | 備考 |
|---|---|---|
| ファイル更新時間 | 8回 / 日 | ー |
| 緯度(latitude) | 505点 | 22.4N-47.6Nで0.05毎 |
| 経度(longtitude) | 485点 | 120E-150Eで0.0625毎 |
| 気象要素 | 12要素 | 海面更正気圧/地上気圧/風のu成分/風のv成分 気温/湿度 下層雲量/中層雲量/上層雲量/全雲量 降水量/日射量 |
| 予報時間 | 39 or 51/ファイル | 39時間(03/06/09/15/18/21 UTC)/ 51時間(00/12UTC) |
緯度×経度×気象要素の単位時系列で分析をしたいので、その要素だけでも 505点 × 481点 × 12要素 = 2,914,860 と300万近くになり、そこが難しいところになります。
パターン別に試行
RDBに行持ちで保持
RDBに入れた場合を考えます。上記のような列持ちは列数の制限に用意に引っかかってしまいます。(例えばPostgreSQLやRedshiftは1600col/Table)
行持ちにすると例えば以下のようになります。
| ファイル更新時刻 | 予報時刻 | 緯度 | 経度 | 要素 | 値 |
|---|---|---|---|---|---|
| 2021-07-15 01:00:00 | 2021-07-15 10:00:00 | 35.6 | 139.71 | temperature | 20.5 |
| 2021-07-15 01:00:00 | 2021-07-15 11:00:00 | 35.6 | 139.71 | temperature | 20.6 |
| 2021-07-15 01:00:00 | 2021-07-15 12:00:00 | 35.6 | 139.71 | temperature | 21.6 |
| 略 |
データロード
一日の毎に9億レコードの挿入が必要。これは不可能で無いにしろ大きな数字ではあります。
505点 × 481点 × 12要素 × 39時間 × 8回/日 = 909,436,320行
データ容量
データ構造的に緯度や経度の情報も重複して持ってしまうのでデータ量が膨大となります。
Redshiftなどで大きなリソース用意すればいけるのかもしれないですが、クエリ要件に対してはあまりにお金がかかると思い止めました。
S3+ Parquet + Athena
Parquet形式でS3に保存されたファイルをAthenaから読み込むことで特定列だけを読み込み可能です。以下のようなParquetテーブルを持つことができれば効率の良いクエリが可能なはずです。
| ファイル更新時刻 | 予報時刻 | 緯度1-経度1-温度 | 緯度1-経度1-湿度 | 緯度2経度1温度 | 略 |
|---|---|---|---|---|---|
| 2021-07-15 01:00:00 | 2021-07-15 10:00:00 | 20.5 | 50.7 | 20.5 | |
| 2021-07-15 01:00:00 | 2021-07-15 11:00:00 | 20.5 | 50.7 | 20.5 | |
| 2021-07-15 01:00:00 | 2021-07-15 12:00:00 | 20.5 | 50.7 | 20.5 | |
| 略 |
データロード
300万列のParquetが作れるのかが、最初の壁でしたが、そこはクリアできました。
Athenaから読もうとしたところエラー。調べてみるとAthenaのテーブルにも 14348列の制限があるようです。
[小ネタ]Athenaのクエリ文字列制限262144 バイトはテーブル作成時に何個までカラムを指定できるか調べてみた | DevelopersIO
Amazon Timestream利用
この要件を別の角度から考えてみると、日本中に置いてあるIoTセンサーから取得した情報の時系列分析に近いなと考え調べたところTimestreamが良さそうでした。確かに監視などのプロダクトにも時系列DB使われているなと思いながら試してみました。
調べてみるとTimestreamには料金計算ツールがあるようなので、これを入力しながら処理を書いてみました。
クエリ
早速データを投入してみると高速でクエリできますし、クエリ時の読み込み箇所も緯度、経度、属性で指定した部分だけを読み込むことができていました。クエリ料金も読み込みスキャン量での課金なので、要件にも合っています。
今回の検証で初めて、クエリまでたどり着きました。
データロード
何も考えずにいくと、一回の更新タイミング毎に1億リクエストが必要になります。 100件毎のバッチでPUTすることで、100万リクエストに減ります。
505点 × 481点 × 12要素 × 39時間 = 113,679,540PUT ⇒ バッチで100万リクエスト
更にマルチメジャーレコードとしてアップすることで、12要素を一つのリクエストに纏められるので、100件毎のバッチ9万リクエストくらいまで落とせます。これなら並列処理して十分現実的な時間で処理可能です。
505点 × 481点 × 39時間 = 9,473,295PUT ⇒ バッチで9万リクエスト
データ容量
ただ、ここまで来て料金見るとデータ容量がかなり高額になっていました。
今回はレイテンシを気にしていないので、マグネティックストアを使っていたので、保存コストは$0.0375/GBのはずです。S3が$0.025/GBなので何故こんなに高くなるのか不思議でCalculatorを調べてみると、ストレージ容量が想定外に大きくなっていました。
理由の一つは、項目名もサイズに組み込まれること。これが大きいのですが、ギリギリまで項目名を短くすることで少しでもストレージサイズへの影響を減らしてみます。
また、以下のCalculatorを見てみると右のStorageSizeが599Byteになっています。そしてMeasureに並んでいるDoubleの項目がそれぞれ50Byteになっていることがわかります。これはDimentionに設定した内容は各Measure毎に保持されることを表しています。クエリが早いわけですね。
つまりは、年間15.4TB程度ずつ溜まっていくことになりそうです。
599Byte × 505点 × 481点 × 39時間 × 8回/日 × 365 ≒ 15.4TB/年

ということで、ストレージサイズがDimentionが大きくストレージサイズに影響してしまい、どうしてもデータのみの場合と比べてストレージが大きくなってしまうことがわかります。
お金はある程度かかるものの、やっと可能性の高いサービスが見つかりました。
再)S3+ Parquet + Athena
Amazon Timestreamを触っていて気付いたのは、緯度、経度、要素名などのディメンションとして使われるデータをファイルパスとしてオフロードできるS3のメリットです。
上記でS3 + Parquetを試した時には全てをParquetで表現していましたが、S3のファイルパスで表現してみる方式を試しました。
緯度と気象要素、ファイル更新時刻をS3のパスで表しました。
s3://bucket/parquet/lat=35.600/field=temperature/update_at=20220715010000/data.parquet
| 予報時刻 | 経度1 | 経度2 | 経度3 | 略 |
|---|---|---|---|---|
| 2021-07-15 10:00:00 | 20.5 | 50.7 | 20.5 | |
| 2021-07-15 11:00:00 | 20.5 | 50.7 | 20.5 | |
| 2021-07-15 12:00:00 | 20.5 | 50.7 | 20.5 | |
| 略 |
データロード
緯度505点×要素数12 = 6060のPUTになるので、S3料金は微々たるものです。処理自体も15分のLambdaでも十分に処理可能です。
データ容量
一部の情報をS3ファイルパスで表現しているので、データとして持つのが予報時間と経度のみになります。ここまで試したパターンの中では、最も容量に無駄がありません。
クエリ
Athenaでクエリ可能です。 要件に合わせて緯度=35.650、経度=139.688の格子点の温度を時系列で取得します。
SELECT updated_at, time, '35.650' as lat, '139.688' as lon, CAST("139.688" AS double) as value FROM "db_name"."table_name" WHERE lat = '35.650' AND field = 't' ORDER BY updated_at, time
上記クエリを実行したところです。スキャンしたデータが2.04KBと本当に必要な部分だけを取得しているのがわかります。
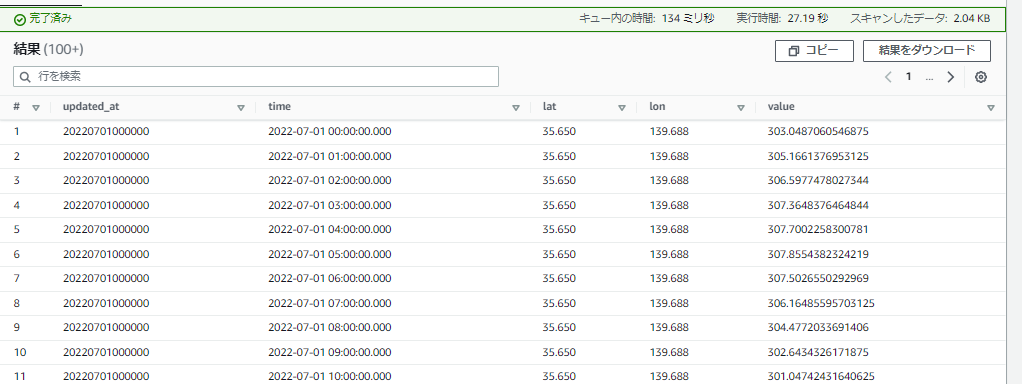
少しクエリに時間がかかるのと、人間が読みやすい結果を得るためのクエリが直感的でないのが、この方法の難点でしょうか・・
再々)S3+ Parquet + Athena
上記で進めていたところ、いつかこの制限にかかることがわかりました。
HIVE_EXCEEDED_PARTITION_LIMIT: Query over table 'default.table' can potentially read more than 1000000 partitions
そこでファイル更新時刻をParquetファイルに組込みました。
s3://bucket/parquet/lat=35.600/field=temperature/data_20210715010000.parquet
| 予報時刻 | 更新時刻 | 経度1 | 経度2 | 経度3 | 略 |
|---|---|---|---|---|---|
| 2021-07-15 10:00:00 | 2021-07-15 10:00:00 | 20.5 | 50.7 | 20.5 | |
| 2021-07-15 11:00:00 | 2021-07-15 10:00:00 | 20.5 | 50.7 | 20.5 | |
| 2021-07-15 12:00:00 | 2021-07-15 10:00:00 | 20.5 | 50.7 | 20.5 | |
| 略 |
これによりパーティション数が固定かつ適切な数になったので、新たにこちらの機能を利用できるようになりました。 Amazon Athena でのパーティション射影 - Amazon Athena
最後に
タイトルに書いた通りこの記事は私個人の検討過程を書いてみています。お世辞にもスマートな道筋とは言えないのですが、誰かの参考になればと思います。
ちなみに、本件はこれからもアイデアあれば、更新していこうと思います。