BigQuery側では一瞬で処理が終わるのに、TableauへのHyper形式の抽出が遅いので調べてみました。
結論
BigQuery公式のJDBCやODBCドライバーのHigh-ThroughputAPIを利用するとTableauの抽出処理のスループットが大幅に向上する場合もある。(注意点有り)
課題と調査経緯
BigQueryのデータをTableauの抽出モードでhyper形式でロードする処理を流したところかなり時間がかかることがわかりました。
調べてみるとTableauの組込みのBigQueryコネクタに設定があることがわかりました。
https://help.tableau.com/current/pro/desktop/ja-jp/examples_googlebigquery.htm
ただ、色々変えてみたのですが速度がでません。
以下がWindowsのネットワークグラフです。 グラフ上の横線は7.7Mbpsです。データを取りにいってはhyper形式に変換マージという処理が複数ジョブで動いているようです。

最初ネットワーク速度も疑ったのですが、ネットワーク帯域の制限を無くしても速度が出ません。 なお、ネットワーク帯域を絞ったSquidのProxyを通した場合の波形は以下のように明らかに帯域がボトルネックになっていることがわかる波形になります。

High-Throughput APIを試す
色々調べているとBigQueryのODBC DriverにHigh-Throughput APIという項目を見つけました。

BigQueryのドライバはSimba Technologies Inc.が提供しており、ドキュメントがGoogleのページにあります。
ODBC and JDBC drivers for BigQuery
High-Throughput APIはBigQuery Storage APIを使っているようで、RESTではなくrpcベースのプロトコルでデータをロードできるようです。
APIの有効化が手順に入っていることからHigh-Throughput APIはBigQuery Storage APIを使っているはずです。以下にあるようにRPCベースのプロトコルなので、RESTよりは早いはずです。
The BigQuery Storage Read API provides fast access to BigQuery-managed storage by using an rpc-based protocol.
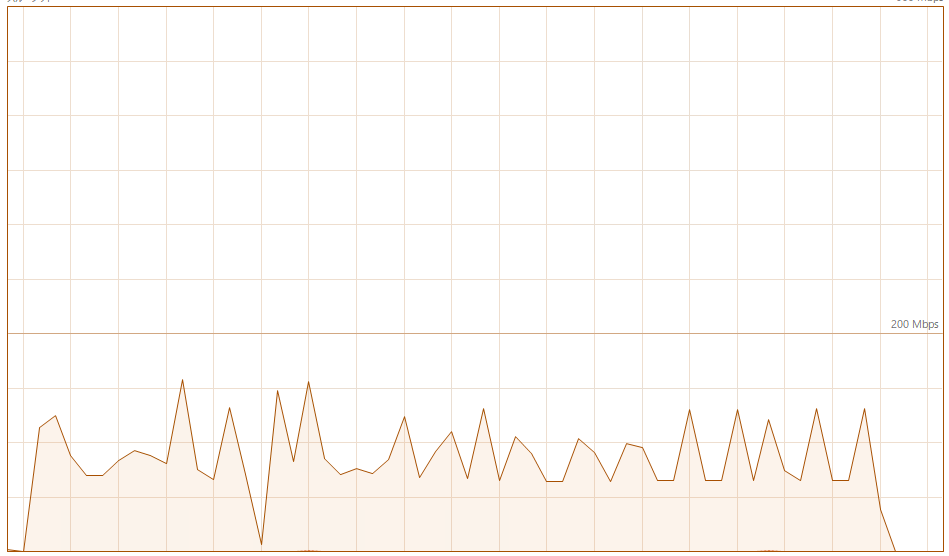
実際に試してみたところが以下になります。波形が全くことなるのと先程は7Mbpsが基準だったのが200Mbpsが基準になっているため速度が全く違うことがわかります。実際にかなり早くなりました。
設定手順
こちらに詳しい手順が記載されています。Tableauのコミュニティ記事でした。
High Throughput Google BigQuery extracts with Simba JDBC driver
注意事項
- Tableauのサポートが受けられるものでは無さそう
- Tableau標準の機能ではないので互換性が無い機能がある(記事でもCASTのエラーが出たと書いてあります)
- 認証にサービスアカウントが必要
ということで注意点やシナリオ毎の確認を前提としますが、使える場面もありそうです。